User-agent: *
Disallow:
Disallow: /extend
Disallow: /install_*
Disallow: /template
Disallow: /core
Disallow: /vendor
Disallow: /application
这个有没有毛病.....
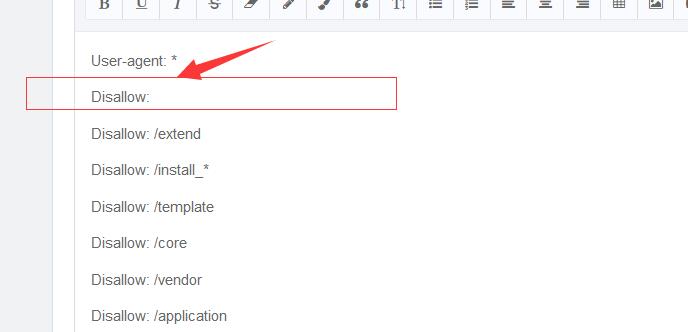
这里是不是禁止了所有.................求指教
其实最好不要写,除非你是特殊行业,不然多少会有影响,真的,参考我的网站
###以前整理了个模板:不知道有没用,自己参考呗!
Robots.txt的相关写法
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /* 这里定义是禁止爬寻目录下面的全部文件
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/ 禁止爬取ab文件夹下面的文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
广州买房留意网 的robots.txt 就是这样的
User-Agent: *###
Disallow:/*?*
Disallow:/wp-includes/
Disallow:/wp-admin/
Disallow:/*.PHP
Disallow:/Disallow:/htdocs/wp-content/themes/wp-training/css/
Disallow:/htdocs/wp-content/themes/wp-training/Disallow:/htdocs/wp-content/themes/wp-training/JS/
Disallow:/htdocs/wp-content/themes/wp-training/css
Disallow:/htdocs/wp-content/themes/wp-training/languages
Disallow:/htdocs/wp-content/themes/wp-training/plugins
Disallow:/htdocs/wp-content/themes/wp-training/upgrade
Disallow:/*
# Sitemap files
Sitemap: Sitemap: Sitemap:
百度站长平台都有诊断Robots文件的功能,想看写法对不对,去那里诊断下就一清二楚了。
###就是和平常说话一样,你允许抓取哪些文件或目录就直接把路径放上去,不允许抓取哪些就放哪些路径。然后*表示通配符。
###你这个要按照蜘蛛协议规则写才可以啊
###去Robots生成器弄一个就好 ,没那么复杂
###Robots格式如下:
- User-agent: * 针对定义搜索引擎类型,*代表对所有搜索引擎蜘蛛,如需指定对哪些爬虫有效(百度蜘蛛:BaiduSpider 谷歌蜘蛛:Googlebot 360蜘蛛:360Spider 搜狗蜘蛛:Sogou Spider 所有蜘蛛:*),需另写明。
- Disallow: / →即禁止抓取的地址。
- Allow: / →即允许抓取的地址。
- “*”和”$” 分别代表通配符和终止符,百度蜘蛛一般用这两个通配符来模糊匹配url。”*”是匹配0或多个以上的的任意字符,”$”是匹配行的结束符。
写法规则,“:”的使用要是英文下的符号,写法后面留一空格,如下举例。
屏蔽整个网站,使用正斜线:
- User-agent: *
- Disallow: /
要屏蔽某一目录以及其中的所有内容,在目录名后添加正斜线:
- User-agent: *
- Disallow: /目录名/
要屏蔽某个具体的网页,就指出这个网页:
- User-agent: *
- Disallow: /网页.htm
要屏蔽网站上的动态链接:
- User-agent: *
- Disallow: /*?*
要屏蔽网站上的css、JS文件:
- User-agent: *
- Disallow: /*.js$
- Disallow: /*.css$
要屏蔽网站上的图片:
- User-agent: *
- Disallow: *.jpg$
- Disallow: *.png$
- Disallow: *.gif$
要屏蔽网站上的文件包:
###
- User-agent: *
- Disallow: /*.zip
可以去百度统计里面还是站长里面的Robots检测的判断一下看看
###你这样就可以了
###你可以去百度站长平台,那边有工具可以检测你写的合不合规 都有说明的
我这边一般是这样写,针对不同的站细节地方再修改,我也不是很懂这个,所以每次添加了Robots文件之后我会去资源管理平台查看一下看有没有提示错误,并把网站的一些链接放进去试一下看有没有被禁止抓取
# Robots.txt file from http://域名
# All robots will spider the domain
User-agent: Baiduspider
User-agent: *
Disallow: /admin/ (禁止爬去后台)
Disallow: /upload/ (禁止爬去upload文件夹)
Disallow: /en/ (禁止爬去en文件夹)
Disallow: /cn/ (禁止爬去cn文件夹)
Disallow: /*?* (禁止爬去动态链接,针对全站静态化的站)
Disallow: /*.PHP (禁止爬去.php结尾的动态链接,针对全站静态化的站)
Disallow: /*.css (禁止爬去样式文件)
Disallow: /cn/ (禁止爬去首页动态链接)
Allow: / 除了禁止的,其他都可以爬去
Sitemap:http://域名/
(有无Sitemap 有就加)
###了解的片面,现在学到了,厉害厉害
###禁止百度抓取
User-agent: Baiduspider
Disallow: /
禁止所有搜索引擎抓取
User-agent: *
Disallow: /
CMS,WordPress等不同后台限制抓取的路径不同,区别对待哈
###删了
###你这样写已经是对的啊,你想知道写的对不对,去百度统计里面还是站长里面有一个Robots检测的
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/78346.html