[导读]:roborts禁止抓取某一个页面怎么写?如不想蜘蛛抓取 http://www.xxx.cn/xx/xxxx.html [?] 页面 User-agent: * Disallow:链接相对地址 如: User-agent: * Disallow:/xx/ 可以参照搜外问答的Robots写法...
roborts禁止抓取某一个页面怎么写?如不想蜘蛛抓取 http://www.xxx.cn/xx/xxxx.html[?] 页面
User-agent: *
Disallow:链接相对地址
如:
User-agent: *
Disallow:/xx/
可以参照搜外问答的Robots写法: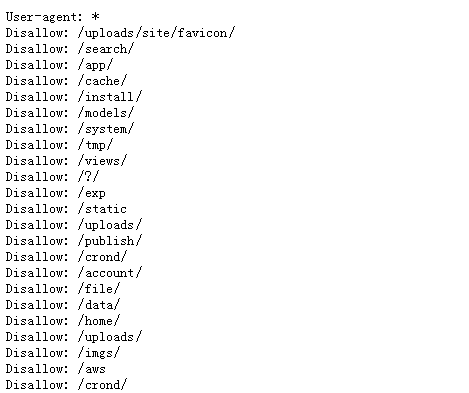
可以参考各大网站的Robots文件是怎么写的,Disallow是禁止抓取的意思,在你的robots文件中加一条Disallow:/xx/xx/.html就可以了
###可以在源代码中加入Nofollow
User-Agent: * 禁止所有搜索引擎蜘蛛抓取。
Disallow: /xx/ 禁止抓取某个目录下的文件
Allow: 允许抓取某个目录文件,一般禁止上面写上了,就可以使用到这个代码。
但有的蜘蛛比较流氓不遵守协议,还是同样会抓取,比如搜狗蜘蛛
###如果只是单纯的不想让蜘蛛爬,那就用rel=“Nofollow”标签加在源文件里,如果是彻底不让抓取就在Robots中加该页面的文件路径,格式跟robots前格式一样,路径\XX\或者其他
###Disallow:/xx/xx/
###我也是同样的问题
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/66763.html