[导读]:网站昨天突然不收录了,之前文章都是秒收。 检查了下日志,发现蜘蛛爬取了大量404页面,分析了下这些404页面,发现这些页面的文章id都是采集数据库里的 比如上面这个蓝底...
网站昨天突然不收录了,之前文章都是秒收。
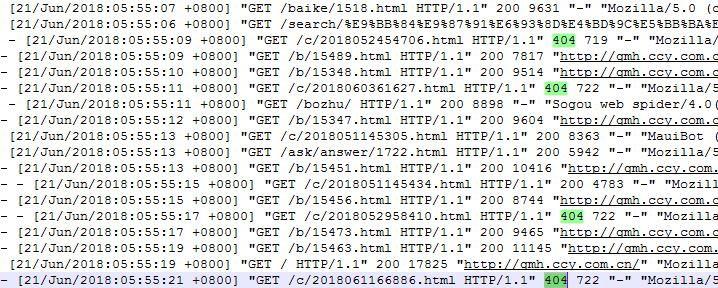
检查了下日志,发现蜘蛛爬取了大量404页面,分析了下这些404页面,发现这些页面的文章id都是采集数据库里的
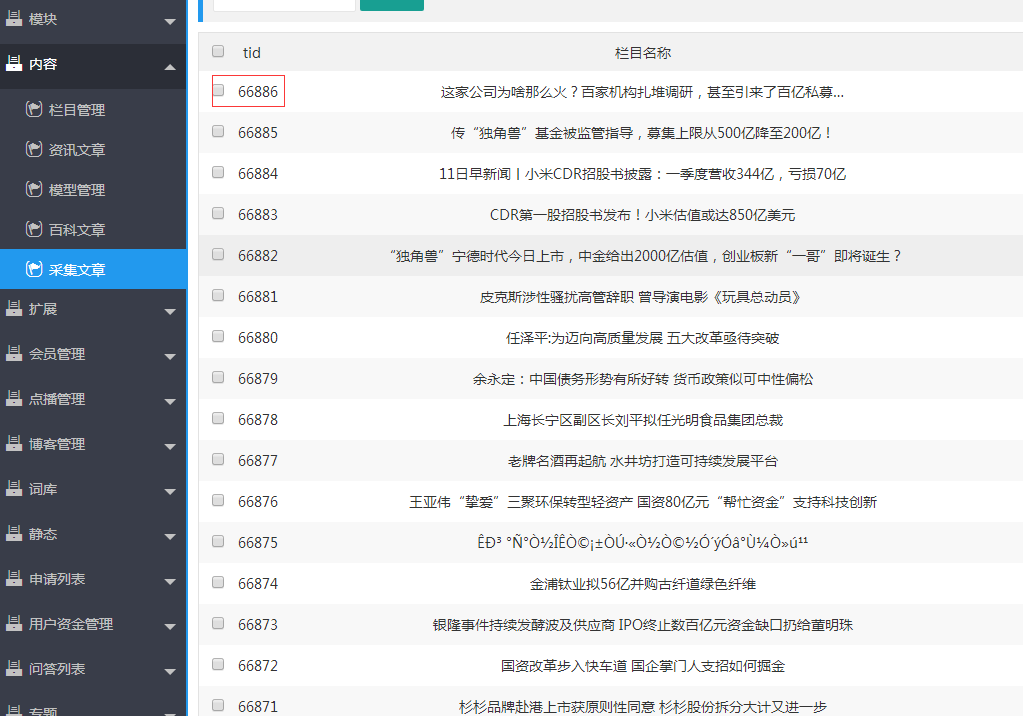
比如上面这个蓝底页面id是66886,这个id的资讯根本没有生成过静态,是调取数据库里的采集文章的信息形成的动态页面
那么问题来了,百度蜘蛛到底是怎么爬取到这个id的,还自动给这个id加上了目录/c/2018061166886(20180611是采集日期),这些文章在采集栏目修改发布后,会在采集栏目消失,出现在资讯文章栏目发布出去。
我想着是不是蜘蛛爬到了后台管理界面,现在把后台给禁抓取了,在后台首页加了个禁止抓取的代码

明天再看看日志,目前网站收录3万5千,蜘蛛这样抓出来的死链接有快4万(数据库的4万篇采集文章)难不成蜘蛛爬了我的数据库?
明天如果还是这么多死链接,我就把这4万个链接全写在robots.txt里面,然后一次性给百度站长平台提交4万个死链接吗?
是不是什么缓存文件或者什么文件里面包含了这些url?
###我也纠结了,我返回代码200的正常页面不抓取,蜘蛛总是抓我网站程序文件,还N多404,什么鬼,我都愁死了,借你楼,做等大神帮忙
Robots限制爬行这些页面
我也是有这个问题,404爬了一千多次,求同问
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/66087.html