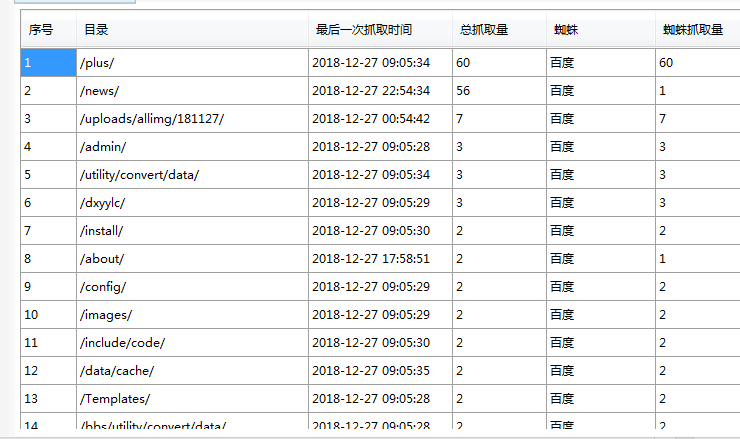
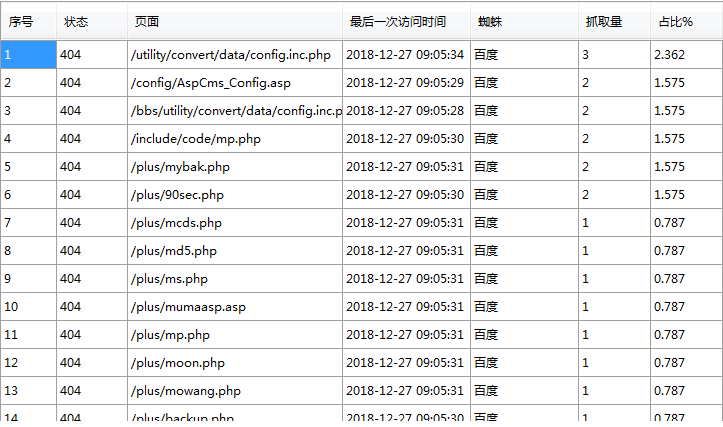
蜘蛛跑到plus里面抓了一堆不知道哪里来的链接,一大堆的404,这是百度自己的原因么,还是因为别的?
有些是伪装的百度蜘蛛,采集或者想看你的网站能否被攻击的,ip地址你反ping一下会发现并不是百度的。这一类的抓取特征就是同一个ip在集中的时间段内爆发式的抓取一堆链接并且都是404,比较好辨认。你打开日志找到这些ip反ping一下,不是百度的直接封掉。或者找技术支持一下,多少时间,多少次访问就屏蔽ip一段时间,不过要看你网站具体情况,有可能会伤害到一定的用户体验和影响正常蜘蛛抓取。如果这些404的抓取ip反ping确实是百度的,去站长平台反馈一下。
###这不是百度蜘蛛,模拟的ua,搞你网站的。
###做好404页面。
屏蔽这些不想被蜘蛛爬取的页面。
###1、你可以去Robots文件添加不让他抓到的PHP文件。(或者没有用的目录也可以)
2、做一个404页面,这样不导致蜘蛛的爬取丢失,跟流量的丢失(记得规则:5秒后跳转回原域名)
###首先你看一下,这些404的文件是不是你网站的文件,如果不是,很有可能是黑客在寻找漏洞想要入侵,然后留下的访问日志。只有蜘蛛的404需要处理,其他的404很多时候并不是网站问题,而是外部的因素。
###你这是织梦做的网站,去把网站的Robots写一下,不让蜘蛛爬取你的一些敏感目录,比如模板目录templets
,plus,include,uploads,special,data,
还有很重要的目录admin,admin是你网站登录后台地址吧,它就别让蜘蛛抓了。
###蜘蛛无目的抓取确实很烦且做了无用功,诊断建议:
文件中禁止抓取指定文件夹。您Robots文件可以添加 Disallow:/plus/ ,就不会出现抓取/plus/文件夹时大量404错误。
2.添加404页面。模板参考地址:
###你把404页面做好 或者你去把这些多余的删除。。这个工程量有点大
###这个不用管 只要你做好404页面就可以
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/59057.html