[导读]:网站做了404,301,日志分析为什么会这样呢? 你牛逼了 ### Robots.txt 可以禁止了 ### 你这是主机自带的查询工具吧 ### 请问你用的是什么网站日志分析工具? ### 你的网站日志里都是...
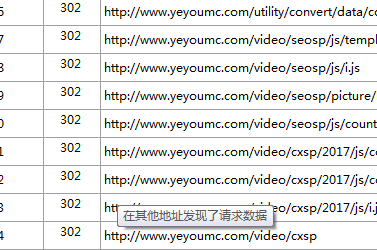
网站做了404,301,日志分析为什么会这样呢?


你牛逼了
###Robots.txt 可以禁止了
###你这是主机自带的查询工具吧
###请问你用的是什么网站日志分析工具?
###你的网站日志里都是正常现象,不要大惊小怪;
200 - 表示服务器成功返回网页;
301(永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
302(临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
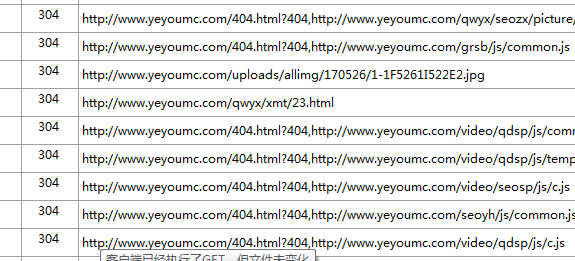
304(未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。 如果网页自请求者上次请求后再也没有更改过,您应将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,进而节省带宽和开销。
404(未找到)服务器找不到请求的网页。
###Robots.txt文件把这个屏蔽掉
###Robots.txt文件别让蜘蛛爬这些文件跟目录就行了
兄弟,建议你先去了解一下404页面和301是干嘛的,网站日志又是干嘛的?还有你要是不想蜘蛛爬行这些目录,你可以在Robots文件那里限制就可以了
本文来自投稿,不代表微盟圈立场,如若转载,请注明出处:https://www.vm7.com/a/ask/47646.html